


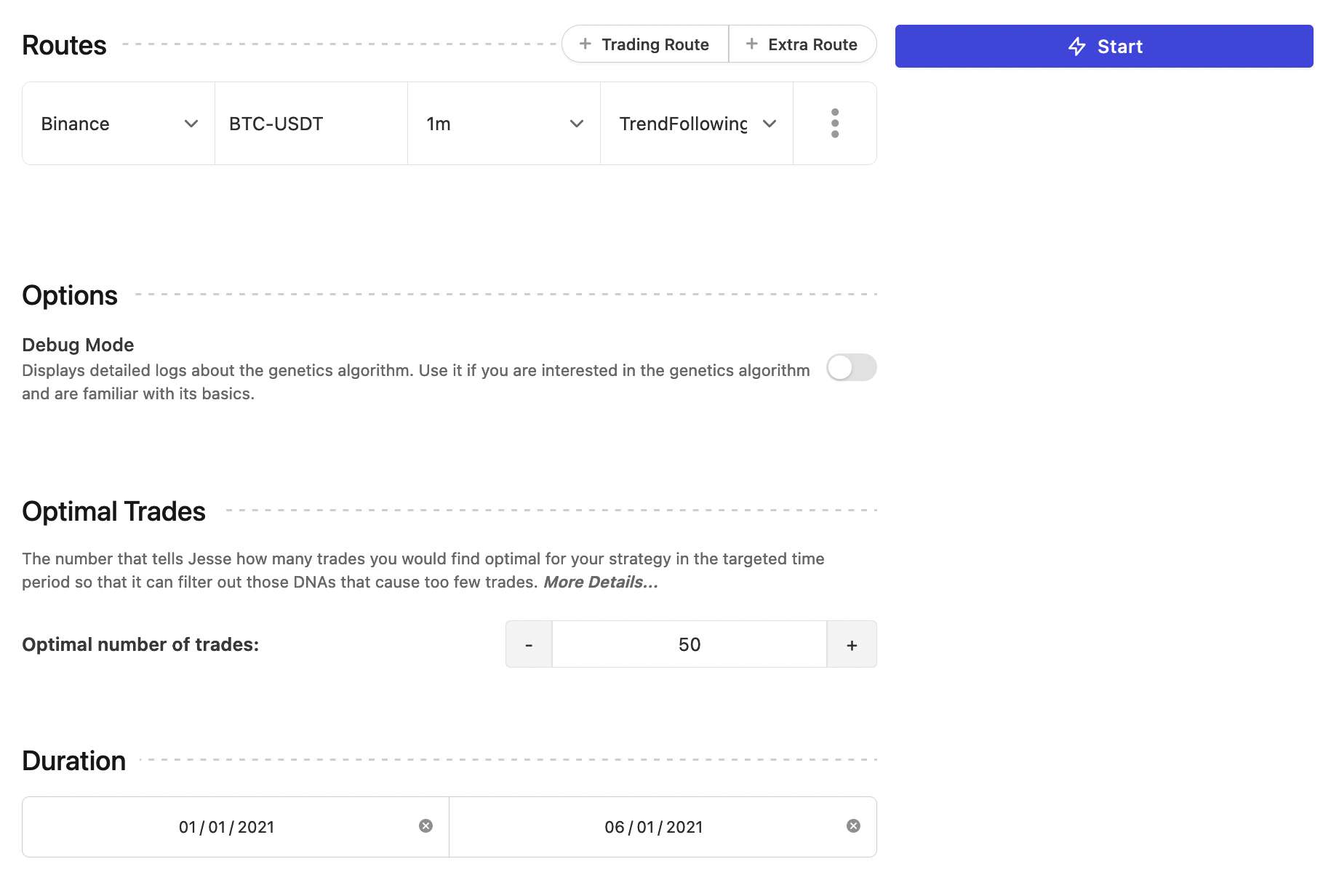
Executing the optimize mode
Executing an optimization session is similar to how you execute a backtest:
Important considerations
There are a few notes to be aware of when executing an optimization session:
- Routes are limited to only "one trading route". You can define multiple extra routes, however.
- To prevent overfitting, the duration of the period should not be too short. For example, don't optimize a strategy for a 3 days period and then expect it to crush it in all market conditions!
- The optimize mode cannot run properly if the strategy's PNL is negative. Its purpose is to improve your PNL, not turn it from negative to positive.
Optimal Trades
The Optimal number of trades input expects an integer that tells Jesse how many trades you would find optimal for your strategy in that time period so that it can filter out those DNAs that cause too few trades.
This is an incredibly important parameter for optimization which helps filter out impractical strategies.
For example, imagine that I have a trend-following strategy that I trade on the 6h timeframe and I usually get 30-60 trades per year in my backtests. You could say that I'll be fine with DNAs that cause my strategy to execute the same number of trades (30-60). But will I be fine if it only made like 5 trades in a whole year but had a higher win-rate? The answer is no. Because such backtest results cannot be trusted in the long term. I want to have the law of big numbers in my favor to stay away from the dangers of over-fitting.
Thus, by setting my Optimal number of trades to a number like 60 I will successfully filter out such impractical DNAs.
The fitness score (which is used to rank DNAs) is then determined by the closeness of a DNA's total to the Optimal number of trades combined with the Sharpe ratio of the DNA.
TIP
When in doubt about the correct value for the Optimal number of trades, try setting it higher than what you have in mind, but not lower.
For example, in my example, the average number of trades per year is 30-60, so I would set Optimal number of trades to 60. I could set it to 100 and it would still work just fine, but if I had set it to like 10, it might have broken some calculations of the optimize mode.
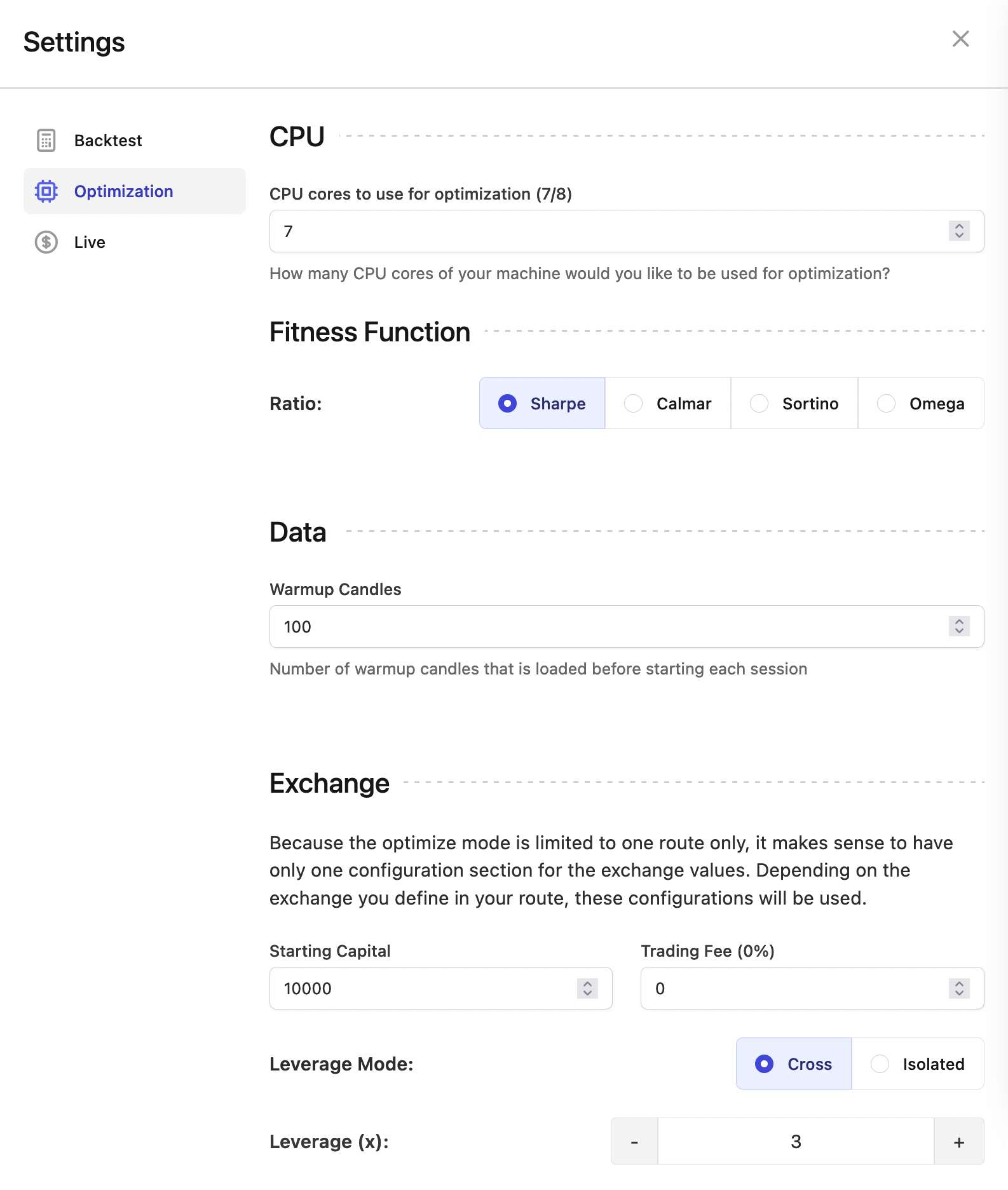
Optimization settings
There's a section in the settings page in the dashboard which allows you to change the settings for the optimization mode:
When is the optimization over?
After starting the optimize mode, first, the initial population is generated. There is a progress bar telling you how long you have to wait until it's done. During this period, no optimization is being done. It's just a random generation of the DNA.
Then, the "evolving" phase begins and the progressbar is back to zero. You will see a progress bar for this phase too, but you don't need to pay much attention to it or expect it to reach 100%.
Remember that the point of the optimize mode is not to find the perfect parameters, but it is to find a few good ones. Why? Because the perfect ones also have a higher chance of being over-fit.
All you need as the result of running the optimize mode is the DNA string. And you can see them at any time in the monitoring dashboard. Hence, once you see a few DNAs that are resulting good in both training and testing set, then copy those DNAs, and use them to run separate backtests on your validation period. If that performed well, then you're good to go.
